

Enterprise AI Solutions: Building AI at Scale for Large Organizations
Most enterprises can prove AI works. A proof-of-concept model predicts churn. A chatbot pilot improves customer service. An image classification model speeds up quality control. Yet 70% of AI projects never move beyond the pilot stage into production at meaningful scale.
The bottleneck isn't ML expertise—it's enterprise-grade infrastructure, governance, and organizational change. A POC runs on Jupyter notebooks and borrowed cloud credits. Production AI at enterprise scale requires orchestrating data pipelines, model deployment, feature engineering, monitoring, compliance, and continuous retraining across thousands of users and petabytes of data.
Enterprise AI solutions are the platforms and practices that move organizations from experimental AI to systematic, scalable, governed AI deployment. This guide covers the architecture, governance decisions, platform evaluation, and organizational patterns that distinguish enterprises that embed AI successfully from those stuck in endless pilots. ai-implementation
What Is Enterprise AI?
Enterprise AI is AI deployed at organization-wide scale—not just one model, but dozens to hundreds of models running across business lines, integrated into mission-critical systems, managed by interdisciplinary teams, governed by policy, and monitored for risk and bias.
Key characteristics:
- Multi-model orchestration: Simultaneously running image, NLP, forecasting, and recommendation models, each with its own lifecycle.
- Production-grade infrastructure: Automated retraining, versioning, rollback, monitoring, and SLA guarantees (99.5%+ uptime).
- Governance and compliance: Audit trails, explainability, bias detection, data lineage, and regulatory alignment (GDPR, EU AI Act, sector-specific rules).
- Organizational scale: Multiple teams (data, ML, platform, business) with clear responsibilities and handoffs.
- Continuous improvement: Models monitored in production; performance degradation triggers retraining or rollback.
Enterprise AI is not a product you buy. It's an operating model—a combination of technology, processes, and organizational structure.
The Enterprise AI Architecture Stack
Here's the typical technology stack for enterprise-scale AI:
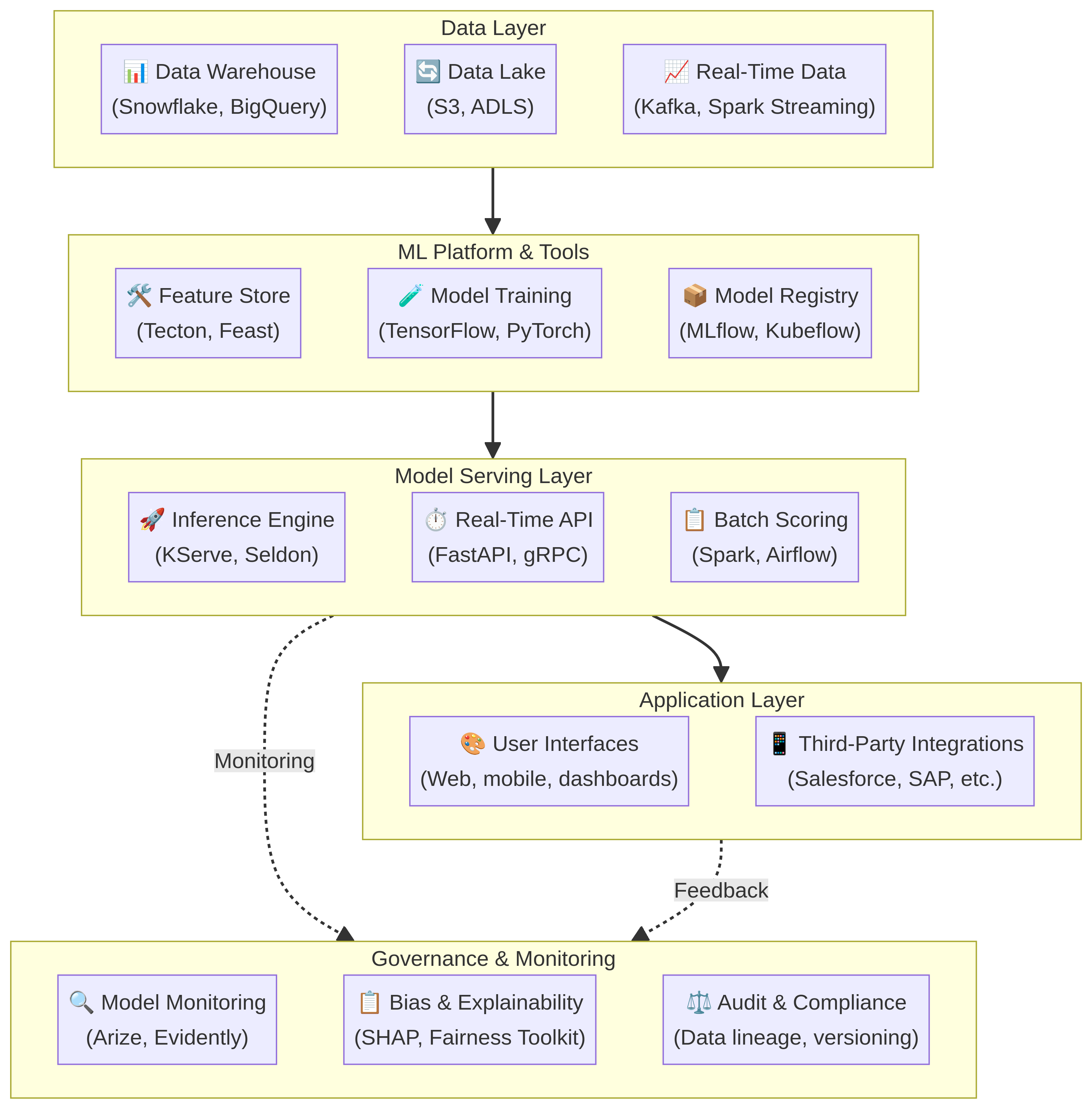
Each layer requires careful selection and integration:
Data Layer: Your ML models are only as good as your data. Enterprise data architectures consolidate data from multiple systems (ERP, CRM, operational databases, IoT sensors) into a centralized warehouse. Snowflake and BigQuery are dominant in cloud; on-premise alternatives include Teradata and Netezza. The key requirement: unified, governed, high-quality data available in real-time or near-real-time.
ML Platform & Tools: Feature engineering (extracting useful signals from raw data) is where 80% of ML work happens. A feature store centralizes this: you define features once (e.g., "customer lifetime value"), and multiple models reuse them. ML training frameworks (TensorFlow, PyTorch, Scikit-learn) stay the same, but orchestration tools (Kubeflow, MLflow) manage versioning, experiment tracking, and reproducibility.
Model Serving: The trained model must deliver predictions in milliseconds to live applications. This requires specialized infrastructure. Batch scoring (generating predictions for all customers overnight) uses Spark or Airflow. Real-time serving (predicting for one customer at 2 AM) uses containerized inference engines with auto-scaling (KServe, Seldon Core).
Application Layer: Models are embedded in business applications. A churn prediction model scores all customers daily; results push to CRM dashboards. A recommendation engine serves personalized suggestions to the web app. Integrations with Salesforce, SAP, and other enterprise systems are critical.
Governance & Monitoring: In production, models degrade. Data distribution shifts. Training data had 60% male customers; production now has 40%. A model that was 95% accurate can slip to 87% without detection. Production monitoring catches this. Explainability tools ensure you understand why the model made a prediction. Audit tools create a compliance trail.
Build vs. Buy: Enterprise AI Platforms
Organizations typically face a choice:
Option 1: Build a Custom Stack
Components: Assemble best-of-breed tools. Data warehouse (Snowflake), feature store (Feast), training framework (Kubeflow), serving layer (KServe), monitoring (Arize).
Pros:
- Flexibility. You choose each component to fit your architecture.
- No vendor lock-in.
- Lower per-unit costs at massive scale (1000+ models).
Cons:
- Requires strong ML platform engineering team (3–5 senior engineers minimum).
- Integration effort. Components don't talk to each other; you build connectors.
- Maintenance burden. Upgrade cycles, version conflicts, operational support.
- Time to value: 12–18 months before first models ship.
Best for: Large enterprises (5000+ employees) with strong engineering talent and multi-year timelines.
Option 2: Enterprise AI Platforms (SaaS)
Examples: Databricks, Dataiku, SageMaker (AWS), Vertex AI (Google), Azure ML (Microsoft).
Pros:
- Integrated. Everything talks. Less glue code.
- Faster time to value. First models in 3–6 months.
- Vendor handles upgrades, security patches, and operations.
- Built-in best practices (monitoring, governance templates).
Cons:
- Less flexible for unusual architectures.
- Vendor lock-in. Switching is painful.
- Per-model or per-user pricing. Can get expensive at 100+ models.
- Feature parity issues. Your favorite tool (e.g., LightGBM) might not integrate smoothly.
Best for: Mid-market and early-stage enterprises (1000–10000 employees) prioritizing speed over flexibility.
Option 3: Hybrid Approach
Use a platform for core workflows (data prep, training, monitoring) and integrate specialized tools for specific use cases. E.g., use Databricks for standard ML, but integrate TensorFlow for deep learning, PyMC for Bayesian analysis, and Hugging Face for LLMs.
This is the most pragmatic approach: platforms handle 80% of use cases, specialists handle the 20% that need custom solutions.
Enterprise AI Governance: The Non-Technical Problem
Technical architecture is 20% of enterprise AI success. The other 80% is governance—answering the hard questions:
Who owns a model in production? If predictions start drifting, who fixes it? If the model is biased against a demographic, who investigates? Typical ownership model: Data science team owns model accuracy; business owner owns business outcomes; platform team owns infrastructure.
How do you prevent model drift? Models trained on 2024 data become stale by 2025 if the world changes. Retraining schedules vary: some models retrain daily, others monthly or quarterly. Decision: automatic retraining on schedule, or human-triggered only?
Who audits for bias? Under EU AI Act and industry regulations, high-risk models (hiring decisions, credit scoring, fraud detection) require bias audits before and after deployment. Who runs these? Who decides if bias levels are acceptable?
What's the change process for models in production? If you change a model (e.g., adding new features), how do you validate before pushing to production? Rolling updates? Canary deployments (new model serves 5% of traffic first)? A/B tests?
How long is a model in production without retraining? Some organizations allow indefinite production; others require regular retraining (every 6 months, annually). Too frequent and you're wasting compute; too infrequent and you drift.
What's your disaster recovery plan? If a model fails, can you rollback to the previous version instantly? Is that rollback automatic or manual?
Enterprises that scale AI successfully have written policies covering all these questions. They assign clear ownership. They document decisions and rationales.
Organizational Structure for Enterprise AI
Successful enterprises structure AI work around these roles:
Data Engineering (4–6 people per 100 ML engineers): Builds and maintains data pipelines, data warehouse, data quality checks. They own the data layer.
ML/Data Science (1–3 per business domain): Builds and trains models. They own training and model development. Typically organized by business domain (marketing, fraud, operations).
ML Platform Engineering (2–4 people): Builds and maintains the ML platform infrastructure (feature store, model registry, serving layer, monitoring). They own tooling.
ML Operations (1–2 per domain): Monitors models in production, identifies performance degradation, triggers retraining, investigates failures. They own model lifecycle in production.
Analytics/Insights (1–2 per domain): Translates model outputs into business insights. They work with business teams to define use cases and success metrics.
For a 100-person company: 2–3 data scientists + 1 data engineer + 1 ML ops works. For a 10,000-person enterprise: 50+ data scientists, 10–15 data engineers, 5–10 platform engineers, 5–10 ML ops specialists.
Scaling AI: From Pilot to Portfolio
Most enterprises follow this progression:
Stage 1: Pilot (Months 1–3)
Single model, high business impact. E.g., churn prediction, fraud detection. Often run on small, clean datasets. Success rate is high (70–80% of pilots work). Funding is easy to justify because ROI is clear and bounded.
Stage 2: First Production Deployment (Months 4–9)
Move the pilot to production with proper infrastructure, monitoring, and governance. First data quality issues appear. First model degradation detected. First retrain needed. Organizational friction emerges: who owns this model long-term?
Stage 3: Second and Third Models (Months 10–18)
Expand to adjacent use cases in same or different domains. Now you need governance for multiple models. Retraining schedules diverge. Cross-team dependencies emerge. ML platform investments start making sense.
Stage 4: Platform Consolidation (Year 2+)
Formalize platform. Standardize deployment processes. Centralize monitoring and governance. Now you can scale from 5 models to 50 models without proportional team growth.
The death valley: Stages 2–3. Pilots worked; production is hard. Org pressure to ship more models faster clashes with reality of data quality, monitoring, and governance. Organizations that invest in platform engineering survive this. Those that don't often kill their AI program.
Key Decisions in Enterprise AI Implementation
1. Real-Time vs. Batch Scoring
Real-Time: Model serves predictions in milliseconds. E.g., recommendation engine at product view time, fraud model on transaction. Requires fast inference infrastructure (Kubernetes, GPU clusters). More expensive but better UX.
Batch: Model scores all entities overnight or on schedule. E.g., churn prediction scores all customers daily; results push to CRM. Cheaper but higher latency. Results appear next morning, not instantly.
Hybrid: Many enterprises use both. Real-time for user-facing, batch for reporting.
2. In-House Models vs. LLMs-as-a-Service
In-house: Train custom models on your data. Full control, data stays internal. Expensive. Requires ML talent.
LLMs-as-a-Service (OpenAI, Anthropic, Google): Use foundation models via API. Fast to deploy, low overhead. Data goes to vendor (privacy concern). Less customization.
Fine-tuning: Fine-tune an open foundation model on your data, deploy in-house. Middle ground. Some privacy, some customization, moderate cost.
Most enterprises adopt hybrid: custom models for proprietary data/logic, APIs for generic NLP/vision tasks.
3. Explainability vs. Performance
Complex models (deep neural networks, gradient boosting ensembles) outperform simple models (linear regression, decision trees) by 10–20%. But they're black boxes. Regulators demand explainability for high-risk decisions.
Options:
- Use explainability tools (SHAP, LIME) on complex models. Adds compute, still slower.
- Use simpler, more interpretable models. Trade 5–10% accuracy for transparency.
- Hybrid: simple model for decisions, complex model for validation.
For regulated decisions (hiring, credit, health), many enterprises choose simpler, more explainable models.
4. Centralized vs. Federated Data
Centralized: All data to one warehouse (Snowflake, BigQuery). Single source of truth. Easy governance.
Federated: Data stays in source systems. ML pulls data on-demand. Harder to govern, slower queries, but better for privacy (EU data localization requirements).
Most enterprises consolidate data centrally, then implement access controls for privacy.
Metrics for Enterprise AI Success
Don't just measure model accuracy. These metrics matter:
Business Impact
- Revenue impact of models in production (e.g., $2M annually from churn reduction)
- Cost savings (e.g., $5M from fraud reduction)
- Efficiency gains (e.g., 40% faster underwriting with automation)
Velocity and Throughput
- Time from idea to production (target: 2–4 months)
- Number of models in production (target: 5 per data scientist annually)
- Retraining frequency and automation rate (target: 80% of retrainings automated)
Operational Health
- Model availability/uptime (target: 99.5%+)
- Mean time to detect model degradation (target: 1–3 days)
- Mean time to remediate (target: 1–2 days)
Data Quality
- % of data meeting quality standards (target: 95%+)
- Data freshness (how recent is data in warehouse?)
- Data lineage tracking (can you trace insights back to source systems?)
Governance and Risk
- % of models with explainability documentation (target: 100%)
- % of high-risk models with bias audits (target: 100%)
- Audit trail completeness (target: 100% of changes logged)
Common Enterprise AI Pitfalls
Pitfall 1: Prioritizing Technical Sophistication Over Business Value Building a Kubernetes cluster for model serving is cool. Shipping a model that makes no business difference is wasteful. Start with business problems, not technology.
Fix: Every model should have a clear owner, defined success metric, and dollar value. No model without these.
Pitfall 2: Siloed Data Each business unit maintains its own data warehouse. ML teams can't access cross-functional data. Models remain siloed.
Fix: Invest in data consolidation. Central data warehouse with role-based access. This is table stakes for enterprise AI.
Pitfall 3: No Model Governance Models ship without documentation, without bias audits, without monitoring plans. In production, models drift silently.
Fix: Create a model governance checklist. Every model requires: documentation, bias audit, monitoring plan, rollback procedure.
Pitfall 4: Treating ML Platform as Capex, Not Opex Building a platform is expensive. Organizations expect it to pay for itself year 1. It doesn't. Most organizations see ROI by year 2–3 when model throughput scales.
Fix: Budget platform investment separately from model development. Expect 18–24 month payoff. Justify on velocity and scalability, not immediate ROI.
Pitfall 5: Hiring Generalists Instead of Specialists One "ML engineer" hired to do everything: data engineering, model training, platform engineering, ops. This scales until you have 5+ models.
Fix: Specialize as you scale. Hire data engineers, ML engineers, platform engineers, ML ops roles. Clear ownership prevents chaos.
Frequently Asked Questions
Q: How much does an enterprise AI platform cost? A: Varies widely. SaaS platforms (Databricks, Dataiku) range $100K–$1M+ annually depending on compute and users. Building a custom stack is $500K–$2M first year (team + infrastructure). Multi-year view makes sense; most enterprises amortize over 3–5 years.
Q: How long until an enterprise AI initiative shows ROI? A: Pilots ROI in 6–12 months. First production model often breaks even within 12 months. Portfolio ROI (10+ models) shows strongly by year 2–3. Enterprises with strong platform engineering show ROI faster (year 1–2).
Q: Do we need a data warehouse before AI? A: Yes. You can't build ML without good data. If your data is siloed and poor quality, fix that first. 6 months of data engineering work upfront saves 12 months of frustration later.
Q: What's the difference between AI and ML? A: In enterprise context, they're used interchangeably. Technically: AI is the broad goal (intelligent systems); ML is the technology (learning from data). Generative AI adds foundation models and large language models to the mix.
Q: Should we build models or use pre-built LLMs? A: Both. Build custom models for proprietary business logic and data. Use pre-built LLMs for generic text/code tasks. Hybrid approach is most practical.
Q: How do I avoid model bias in production? A: Define fairness metrics (demographic parity, equalized odds). Audit training data for representation. Monitor predictions in production for bias drift. Document mitigation steps. For regulated decisions, involve compliance and legal.
Q: What's the EU AI Act impact on enterprise AI? A: High-risk applications (hiring, credit scoring, law enforcement) require human oversight, documentation, and bias audits. Prohibited applications are banned. General ML is unregulated. Compliance is evolving; assume 2–3 year implementation timeline for covered applications.
Start Building Enterprise AI
Enterprise AI is a multi-year journey. But enterprises that commit—investing in data, platform, governance, and organizational change—see transformative returns: 20–40% efficiency gains, new revenue streams, and competitive advantage.
The key is starting with clarity: clear business problems, strong data foundations, and realistic timelines. Platform investment pays off at scale (10+ models).
Digital Colliers specializes in enterprise AI implementation—from strategy through production. We help define your AI architecture, select platforms, build governance frameworks, and scale from pilots to portfolios.
If your organization is ready to move AI beyond pilots, let's talk about your strategy, data readiness, and organizational structure. Our enterprise AI team can help you avoid the common pitfalls and accelerate time to impact.
Schedule a discovery call today.