

LLMOps: The Complete Guide to Operating Large Language Models in Production
Moving a large language model from notebook experiment to production-grade system is where the real work begins. Most organizations discover this the hard way: a promising proof-of-concept fails in production due to cost explosion, poor response quality, or monitoring blind spots. LLMOps—the discipline of operating large language models reliably and cost-effectively—is what separates successful AI implementations from expensive failures.
This guide walks you through the operational framework that makes LLMs work in production. Whether you're deploying GPT-based applications, fine-tuning private models, or managing a fleet of language model endpoints, understanding LLMOps principles will save you months of firefighting and significant budget overspend.
At Digital Colliers, we help European enterprises build end-to-end AI implementation strategies that include operational readiness from day one. This guide reflects lessons learned across dozens of production LLM deployments.
What Is LLMOps?
LLMOps is the operational discipline that ensures large language models deliver consistent, high-quality outputs while remaining cost-efficient and compliant. Think of it as MLOps evolved for the specific challenges of language models: handling variable latency, managing prompt performance, controlling inference costs, and ensuring output quality without human review of every response.
Unlike traditional machine learning operations, LLMOps deals with fundamentally different constraints:
- Non-deterministic outputs: The same prompt can return different answers, making traditional accuracy metrics less meaningful.
- Cost-per-inference variability: Token consumption varies wildly based on input length and output complexity.
- Latency sensitivity: User-facing applications require sub-second responses, but complex reasoning takes longer.
- Prompt-driven behavior: Model outputs are shaped primarily by prompt engineering, not training data.
- External dependencies: Most production systems rely on third-party model APIs (OpenAI, Anthropic, etc.), creating vendor lock-in and rate-limit concerns.
LLMOps addresses these challenges through a structured lifecycle that moves from development through deployment, monitoring, and continuous improvement.
The LLMOps Lifecycle Framework
The core of successful LLMOps is understanding the four-phase operational cycle:
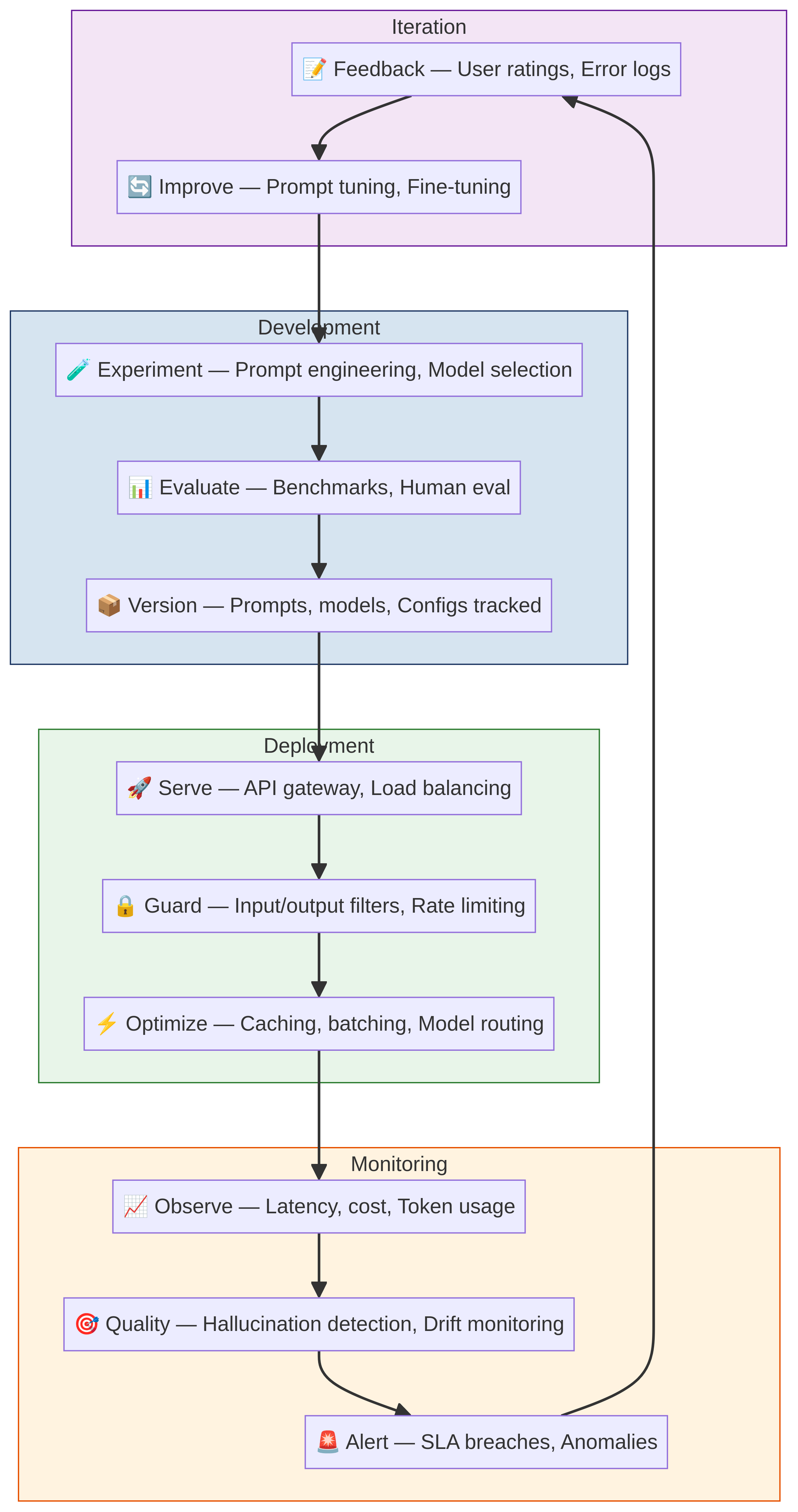
The LLMOps lifecycle: a continuous cycle of development, deployment, monitoring, and iteration that ensures models stay optimized and reliable.
Each phase builds on the others. Let's walk through what happens in each.
Phase 1: Development (Experiment → Evaluate → Version)
Development is where you establish baseline model behavior and confirm it solves your problem before moving to production.
Experimentation starts with prompt engineering. You'll test multiple prompt strategies, model versions, and parameter configurations. Use a structured prompt library rather than ad-hoc testing—tools like LangChain, LlamaIndex, or custom frameworks help organize these experiments.
Key decisions in this phase:
- Which model? GPT-4, GPT-4 Turbo, Claude, Llama, or a fine-tuned alternative? Larger models generally perform better but cost more per token.
- What prompt structure? Few-shot examples, chain-of-thought, system instructions, and role-playing all affect output quality differently.
- Which parameters? Temperature (creativity vs. consistency), top-p (diversity), max_tokens (length control), and frequency penalties all shape behavior.
Evaluation comes next. You can't evaluate every output manually—establish metrics that predict real-world quality. Common LLMOps metrics include:
- Relevance: Does the output answer the user's question? (Benchmark against human labels)
- Hallucination rate: How often does the model make up facts or confidently state things it shouldn't know? (Test against known false statements)
- Latency: How long does generation take? (Set SLAs like "p95 < 800ms")
- Cost: What's the token consumption per request? (Calculate $/request)
- Consistency: Do similar inputs produce similar outputs? (Run 5 variations of the same prompt)
Use a test set that represents real-world usage—if your users ask support questions, test on real support questions. If they're asking coding questions, test on code problems.
Versioning is where you lock in a working combination of model, prompt, and parameters. Store these as configuration files in version control. A version might look like:
version: v1.2.3
model: gpt-4-turbo
prompt: ./prompts/customer-support.md
temperature: 0.5
max_tokens: 1024
top_p: 0.9
evaluation_metrics:
relevance: 0.87
hallucination_rate: 0.02
latency_p95_ms: 650
cost_per_request: $0.008
This is your production baseline. You'll compare all future experiments against it.
Phase 2: Deployment (Serve → Guard → Optimize)
Deployment is where the model moves behind an API and must handle real traffic, cost constraints, and safety requirements.
Serving means choosing your infrastructure. Options include:
- Managed APIs (OpenAI, Anthropic, Azure OpenAI): Simplest to operate, highest per-token cost, no data residency control.
- Cloud endpoints (SageMaker, Vertex AI, Lambda): More control, moderate cost, requires infrastructure management.
- Self-hosted (vLLM, TensorRT-LLM, Ollama): Lowest cost at scale, highest operational complexity, full data control.
For most European B2B applications, managed APIs are pragmatic: you pay for simplicity and compliance support. Self-hosting makes sense only if you're processing millions of tokens monthly or have strict data residency requirements.
Guarding protects the system from misuse, cost explosion, and quality degradation. Implement guardrails:
- Rate limiting: Cap requests per user, API key, or tenant.
- Token budgets: Set daily/monthly token spend caps per customer.
- Input validation: Reject obviously malformed or adversarial prompts.
- Output filtering: Catch hallucinations, PII leakage, or policy violations before returning responses.
- Latency enforcement: Timeout requests that exceed your SLA.
A practical guardrail example: if a user's request would cost > $0.50 to process, require explicit approval first. This prevents a typo from costing thousands.
Optimization for cost is the dominant concern. Once your model is live, focus on reducing tokens per request:
- Prompt optimization: Shorter, clearer prompts often work as well as longer ones.
- Retrieval optimization: If using RAG (retrieval-augmented generation), fetch only the most relevant documents to reduce context length.
- Output length control: Set reasonable max_tokens limits rather than allowing unbounded generation.
- Caching: Cache identical requests and responses—many LLM APIs offer prompt caching at 90% discount.
- Model downgrade testing: Does Claude 3 Haiku work for this task instead of Claude 3 Opus? Test weekly.
Token costs scale linearly with usage. A 10% prompt reduction on 10M monthly tokens saves $1,000/month.
Phase 3: Monitoring (Observe → Quality → Alert)
Once deployed, you need visibility into what's actually happening. Monitoring LLM systems is different from traditional software because outputs are probabilistic—a single bad response doesn't mean something broke; a pattern of bad responses does.
Observation means logging everything:
- Every request: timestamp, user, input length, tokens used, latency, cost.
- Every response: output length, model version, timestamp.
- Errors and failures: timeouts, API errors, malformed outputs.
Use a monitoring tool like Datadog, New Relic, or Grafana to centralize this data. Query patterns matter: "What's our average cost per request?" "How many requests hit the token limit?" "Which prompts timeout most often?"
Quality monitoring is where LLMOps diverges from traditional MLOps. Set up dashboards for:
- Output quality score: Sample responses and score them 1-5 on relevance. Calculate the percentage of "good" responses (4-5).
- Hallucination detection: Use a cheaper LLM to evaluate whether responses contain false claims. Flag these for review.
- User feedback: Implement thumbs-up/thumbs-down buttons. Track the ratio of positive to negative feedback.
- Error rates: Track 4xx and 5xx responses, timeouts, and rate-limit hits separately.
- Drift detection: Compare this week's quality metrics to last week's. A 5% drop in quality score deserves investigation.
Alerting means setting thresholds that trigger action:
- If quality score drops below 0.80 for 2+ hours → page on-call.
- If daily cost exceeds budget by 20% → alert finance and ops teams.
- If hallucination rate exceeds 5% → rollback to previous prompt version automatically.
- If p99 latency > 2s → trigger scaling or failover to a faster model.
Automatic rollback is powerful: if a new prompt version degrades quality, revert it immediately and alert the team to investigate offline.
Phase 4: Iteration (Feedback → Improve → back to Experiment)
Iteration closes the loop. Quality signals from production feed back into development, creating a continuous improvement cycle.
Feedback collection sources:
- Production monitoring (quality scores, error rates, latency).
- User feedback (ratings, complaints, support tickets).
- Cost analysis (where are you overspending per feature or customer?).
- Competitive benchmarking (how do you compare to similar solutions?).
Improvement priorities typically fall into three buckets:
- Quality: Prompt engineering, switching models, adding retrieval context.
- Cost: Token optimization, caching, model downgrade, batching.
- Latency: Infrastructure scaling, early stopping, output streaming.
Pick one and experiment. Implement the change in a shadow or canary deployment (10% of traffic), measure it against your baseline, then decide whether to roll out fully.
Common iteration experiments:
- New prompt structure reducing hallucination from 5% to 2%.
- Shorter prompt cutting tokens by 15% with no quality loss.
- Switching from GPT-4 to GPT-4 Turbo saving 30% cost at 95% quality parity.
- Adding RAG reducing context length by 40%.
Run these as A/B tests. Measure for at least 1 week of production traffic. Document the results. The best teams keep a running log of every change, its metrics, and whether it shipped.
LLMOps vs. Traditional MLOps: Key Differences
Traditional MLOps assumes a trained model that produces deterministic outputs. LLMOps operates in a different regime:
| Aspect | MLOps | LLMOps |
|---|---|---|
| Model change | Retraining (weeks) | Prompt/config swap (minutes) |
| Performance metric | Accuracy on test set | User-rated quality in production |
| Cost model | Fixed (compute per prediction) | Variable (tokens per request) |
| Debugging | Inspect weights, feature importance | Analyze prompts, examples, parameters |
| Iteration speed | Weeks (data, training, evaluation) | Days (prompt, config, evaluation) |
| Failure modes | Overfitting, data drift, concept drift | Hallucination, prompt sensitivity, cost explosion |
The upshot: LLMOps teams move faster but need tighter monitoring, because changes can break production in subtle ways.
Building Your LLMOps Stack
A minimal production LLMOps setup requires:
- Model serving: Managed API (OpenAI, Anthropic) or cloud endpoint.
- Prompt management: Version-controlled prompt library (Git + structured YAML or a tool like Prompt Management).
- Monitoring: Logging (DataDog, New Relic, CloudWatch) + quality scoring.
- Cost tracking: Built into logging or a dedicated cost tool (OpenAI Usage API, Anthropic's dashboard).
- Evaluation framework: Notebook + datasets + scoring functions.
As you scale, add:
- Automated guardrails and output filtering.
- A/B testing framework for prompt experiments.
- Fine-tuning pipeline (if using private models).
- Caching layer (Redis, built-in API caching).
Real-World LLMOps Challenges
Here are problems every team hits:
Cost explosion: A mistuned parameter or verbose prompt can increase tokens 5x overnight. Monitor daily spend and set alerts at 120% of budget.
Prompt brittleness: A prompt that works perfectly for 99% of inputs fails spectacularly on the other 1%. Sample edge cases heavily in evaluation.
API downtime: OpenAI or your provider goes down, and users can't use your app. Implement fallback strategies: queue requests, reduce quality gracefully, or have a backup model.
Hallucination creep: Quality starts high, drifts down over weeks as model behavior changes or user inputs shift. Weekly quality audits are essential.
Vendor lock-in: Switching from GPT-4 to Claude mid-production is risky. Design your abstraction layer to swap model APIs easily.
Cost Optimization in LLMOps
Token costs dominate operational budgets. Here's how to optimize:
Prompt engineering: Clearer, more structured prompts often use fewer tokens and produce better outputs. Invest in this.
Retrieval optimization: If you're using RAG, don't retrieve 50 documents—retrieve 5 highly relevant ones. Cut context length by 80%, save 80% on tokens.
Caching: OpenAI and Anthropic now offer prompt caching. If you have repeated queries with common prefixes (like system instructions), cache them at 90% discount.
Batching: If your use case allows, batch requests. Processing 100 requests together is cheaper than 100 separate API calls.
Model selection: Smaller models often work. Test GPT-4 Turbo instead of GPT-4, or Claude 3 Haiku instead of Claude 3 Opus. Measure quality—if you're at 95% parity, ship it.
Output length: Enforce max_tokens. If a user asks for "a summary," they don't need 2,000 tokens.
One client reduced monthly LLM costs by 40% through these tactics, with zero quality loss.
Compliance and Safety in LLMOps
European organizations face strict data governance:
- GDPR: Don't send personal data to third-party LLM APIs without contracts. Use on-premise or private deployment options if required.
- Output safety: Implement filtering to catch toxic, illegal, or proprietary-leaking outputs before users see them.
- Audit trails: Log every request, response, and user interaction for compliance review.
- Consent: Inform users that LLM-generated content is involved. Some jurisdictions require explicit consent.
When choosing a managed API, verify their data handling: OpenAI and Anthropic both offer enterprise agreements that won't train on your data. Clarify this contractually.
Measuring LLMOps Success
The goals of LLMOps are straightforward:
- Reliability: 99.5%+ uptime, predictable latency (p99 < 1s), zero critical bugs.
- Quality: 80%+ of responses rated good/excellent by users.
- Cost: < $X per request (depends on your business model).
- Speed: New iterations deployed in < 1 week.
Track these in a dashboard. Review weekly. If quality drops, investigate immediately. If cost increases 20%, find out why.
FAQ
Q: Do we need to fine-tune a model for LLMOps?
A: Not usually. Prompt engineering and retrieval augmentation solve 90% of problems faster and cheaper than fine-tuning. Fine-tuning makes sense only if you're processing millions of tokens monthly and prompt optimization has hit diminishing returns.
Q: How often should we update our prompts in production?
A: Every 1-2 weeks, if you're disciplined about experimentation. Test in shadow mode first. A/B test for 3-5 days before full rollout. Bad prompt updates are the #1 cause of quality crashes—move carefully.
Q: What's a realistic LLM cost for a B2B SaaS product?
A: Depends on use case, but typically $0.01–$0.50 per user interaction. If you're spending $1+ per request, your prompts are too verbose or your model is overkill. Optimize aggressively.
Q: How do we handle hallucinations?
A: Detection + filtering. Use a second LLM call to validate facts, retrieve documents to ground responses in truth, or add explicit instructions ("Only use information from the provided documents"). Pure hallucination elimination is impossible, but you can reduce it to <2%.
Q: What's the difference between LLMOps and prompt engineering?
A: Prompt engineering is craft—writing and tuning prompts. LLMOps is engineering—building the systems, monitoring, cost controls, and feedback loops that keep those prompts working reliably at scale.
Q: Should we use open-source models or APIs?
A: APIs are simpler to operate; open-source models are cheaper at massive scale. Start with APIs. If you hit 100M monthly tokens, revisit open-source.
Ready to operationalize your LLM deployment? Digital Colliers helps enterprises build production-ready LLMOps infrastructure, from evaluation frameworks to cost optimization to compliance. We've deployed LLM systems for B2B companies across Europe. Contact us about AI implementation to discuss your operational readiness.